Fine-tuned knowledge agents are specialized AI systems built by adapting pre-trained language models like GPT to perform specific, high-impact tasks using domain-specific data. Instead of relying solely on broad general knowledge, these agents learn from real-world examples, be it in customer service, healthcare, or legal operations, to generate more accurate, relevant, and reliable outputs.
In this article, we’ll explore how fine-tuning works, why it matters, and how it transforms general models into domain experts. From technical processes to strategic advantages, this guide covers everything you need to understand the power and potential of fine-tuned knowledge agents.
What Is Fine-Tuning in AI?
Fine-tuning is the process of adapting a pre-trained language model to perform a specific task more accurately by training it on smaller, domain-specific datasets.
Rather than training a model entirely from scratch, we begin with a foundation model—like GPT or LLaMA—that already understands general language patterns, and then refine it using task-specific examples. This approach drastically reduces training time, computational load, and data requirements, making it far more efficient than building a model from the ground up.
From our experience deploying fine-tuned models across multiple industries—from logistics to healthcare—this method gives us the strategic flexibility to adapt general LLMs to highly specialized tasks such as retrieving structured data, summarizing medical records, or navigating legal documents. Whether we’re fine-tuning a chatbot for customer service or an agent for compliance review, the result is always the same: a model that retains general intelligence but delivers expert-level performance.
Fine-Tuning vs. Transfer Learning: What’s the Difference?
While often used interchangeably, fine-tuning is actually a form of transfer learning. In transfer learning, we take an existing model trained on one task and repurpose it for a new, but related task. For example, a model trained on general text data might be transferred to analyze medical imaging reports or financial documents.
Fine-tuning, however, goes one step further. It doesn’t just transfer capabilities—it continues training the model on highly specific, labeled data to better capture the nuances, tone, and task-specific requirements of the target domain. This makes it especially effective when we need a system that performs with consistency, relevance, and accuracy in narrow or sensitive domains.
Why Fine-Tuning Matters for Knowledge Agents
For AI agents to become genuinely useful in real-world workflows, they need more than general language skills—they need contextual awareness, domain fluency, and adaptive intelligence. Fine-tuning enables exactly that. We’ve seen how agents built with pre-trained models like Cohere’s Command or Meta’s LLaMA 2 can evolve into domain-specialized assistants when fine-tuned on curated datasets from customer queries, support tickets, annotated contracts, or medical case files.
In essence, fine-tuning transforms foundation models into fine-tuned knowledge agents—capable of handling complex tasks, interacting fluently with structured and unstructured data, and delivering outputs that are accurate, relevant, and ready for enterprise-scale deployment. For us, this has been the turning point where AI moves from being a helpful tool to becoming a trusted, knowledge-driven partner in business operations.
What Are Fine-Tuned Knowledge Agents?
Fine-tuned knowledge agents are intelligent systems powered by large language models (LLMs) that have been adapted to specific domains using fine-tuning techniques. We start with a pre-trained model—a general-purpose foundation that understands language patterns broadly—and then specialize it through additional training on smaller, high-quality datasets tailored to our target use case. These agents retain the flexibility and fluency of the original model while gaining deep, domain-specific knowledge.
In our own work deploying AI agents across industries, we’ve seen how fine-tuned models outperform general models when faced with complex real-world tasks like processing legal contracts, analyzing patient records, or responding to nuanced customer inquiries. They understand terminology, intent, and context with remarkable accuracy because their internal weights and parameters have been optimized for a very specific operational goal.
How They Combine General LLMs with Task-Specific Optimization
A foundation model like GPT or LLaMA is trained on large-scale datasets—millions of examples from across the internet. This makes it well-versed in general knowledge, syntax, and even reasoning. But when we want an agent that understands medical terminology, supply chain workflows, or company-specific jargon, general knowledge isn’t enough.
That’s where fine-tuning comes in. We feed the model structured, labeled data relevant to a specific task—like handling customer service queries or summarizing clinical reports. During this process, the model adjusts its internal parameters without forgetting its foundational language skills. The result is an agent that performs with precision, clarity, and consistency, even in high-impact business environments.
How They Differ from Generic AI Agents
Generic AI agents often rely on prompt engineering or retrieval-augmented generation (RAG) to guide outputs. While those techniques are valuable, they still depend heavily on the model’s base capabilities and external data sources at response time. They lack the deep internal understanding of specialized domains, which can lead to inconsistent, hallucinated, or superficial outputs.
Fine-tuned knowledge agents, on the other hand, internalize their training. They don’t just search or guess—they “know” the domain because it’s encoded into their fine-tuned weights. When we deployed a fine-tuned model for a legal tech client, the difference was night and day: instead of generic answers, the agent responded with clause-level analysis, using correct legal terms, formats, and interpretations. That’s the real power of fine-tuning.
Core Traits of Fine-Tuned Knowledge Agents
Domain Specialization
These agents are trained on domain-specific inputs—from annotated contracts to clinical datasets—allowing them to understand the context, terminology, and structures of their operational environment.
Targeted Knowledge
They access relevant, high-value data during training, rather than relying solely on prompts or real-time retrieval. This makes them capable of answering complex questions with clarity and confidence.
Adaptive Intelligence
Because the training is ongoing and customizable, we can fine-tune agents repeatedly to reflect changing data, new use cases, or updated business requirements—without starting from scratch.
Real-World Task Handling
Unlike generic models, these agents excel in real-time applications. Whether it’s managing calendars, generating reports, or presenting analytic insights, they function as capable AI teammates rather than just passive tools.
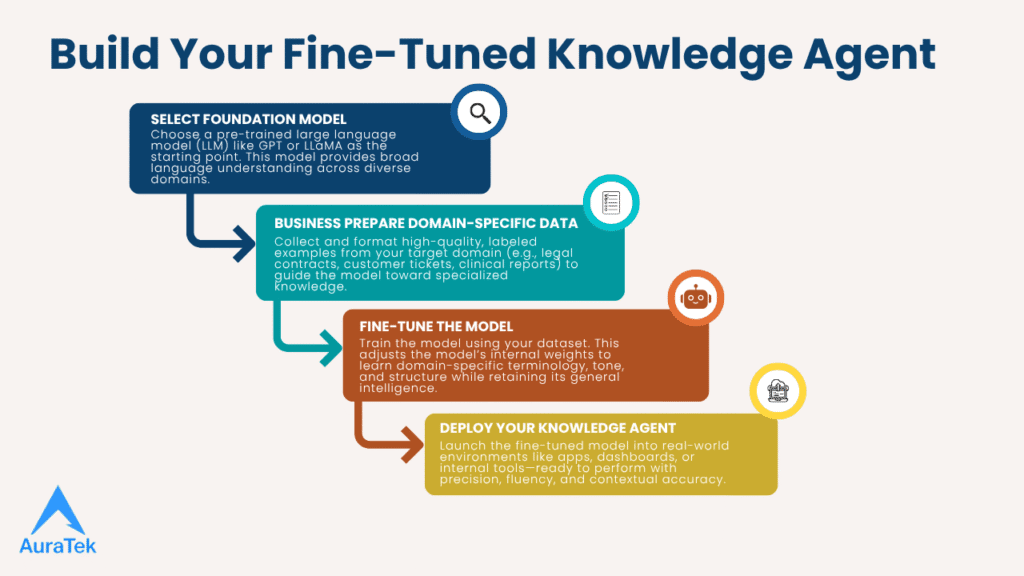
How Fine-Tuning Works: Step-by-Step Breakdown
Fine-tuning may seem like a complex endeavor at first glance, but when broken down into its core stages, the process becomes not only manageable—but incredibly empowering. We’ve gone through this workflow multiple times across sectors like healthcare, SaaS, and finance, and each time, the result has been a high-performance, task-optimized knowledge agent that delivers real-world impact. Let’s walk through the exact steps we follow when building fine-tuned models that go beyond general AI capabilities.
Start with a Foundation Model
Our journey begins by selecting a pre-trained large language model (LLM) that has already been trained on massive general-purpose datasets—typically sourced from the internet, books, or academic data. Models like GPT, LLaMA, or Cohere’s Command are some of the most popular starting points because of their strong architecture, multimodal capabilities, and proven performance across various NLP tasks.
We assess these models based on:
- Domain suitability: Can the base model be adapted to legal, medical, or customer support scenarios?
- Model architecture: Transformer-based vs. hybrid designs, parameter sizes, and attention mechanisms.
- Licensing: Open-source flexibility vs. commercial SLAs, especially for enterprise environments where usage rights are critical.
This step sets the foundation for everything that follows.
Prepare Domain-Specific Data
Once we’ve locked in the foundation model, it’s time to gather domain-specific data that will train the model to specialize. This is one of the most critical phases—the quality of your training data determines the intelligence of your agent.
We typically:
- Collect datasets from internal knowledge bases, customer queries, medical reports, or financial documents.
- Clean the data by removing duplicates, inconsistencies, and irrelevant entries.
- Annotate the data, marking important sections or entities manually or using automated tools.
- Format the dataset into a structure the model understands, most commonly using JSONL, where each line is an instruction-response pair. For example:
json
{“instruction”: “Summarize this contract clause”, “response”: “This clause defines the arbitration process in case of dispute.”}
The better structured the input-output training pairs, the faster and more accurate the model learns.
Set Training Parameters
Before training begins, we must define how the model will learn. This is where hyperparameter tuning comes into play.
The three most crucial parameters:
- Learning rate: How quickly the model updates its internal weights after seeing each batch of data. Too fast, and it might overfit; too slow, and it may fail to learn (underfitting).
- Batch size: How many training examples the model sees at once. This affects both training speed and memory usage.
- Epochs: The number of times the model loops over the entire dataset.
We also decide whether to freeze certain layers of the model—typically the earlier layers, which carry general knowledge. This preserves the base understanding of language while allowing later layers to be updated for task-specific adaptation.
Run the Fine-Tuning Process
Now comes the computational heavy lifting.
We run the fine-tuning process on cloud infrastructure—using GPUs or TPUs for faster training and distributed compute. Platforms like Hugging Face, Google Cloud, and Oracle Cloud Infrastructure (OCI) offer scalable environments with built-in support for deep learning pipelines.
During training:
- The model processes data in batches, adjusting its weights to minimize error.
- We monitor key metrics like loss curves and training steps using visual dashboards.
- Early signs of overfitting (where performance improves on training data but worsens on validation data) are managed with techniques like early stopping or regularization.
Once completed, the fine-tuned model is saved with a unique version ID for traceability and deployment.
Evaluate Performance
We never assume a model is ready just because training is complete. We test it thoroughly against a validation dataset to ensure it performs reliably on unseen examples.
Common evaluation metrics:
- Accuracy: How often the agent gives the correct response.
- Precision: How many of the agent’s positive predictions were actually correct.
- Recall: How many of the correct answers the agent successfully identified.
- F1 Score: A balanced measure combining precision and recall.
We typically run multiple iterations, tweaking training parameters or cleaning up data further until we see the model hitting our quality benchmarks.
Deploy and Monitor
Once the model is validated, we deploy it to production environments—usually within cloud-based applications, internal tools, or embedded systems. From there, the fine-tuned knowledge agent starts delivering real-time outputs, interacting with users, documents, or systems based on the knowledge embedded during training.
But our job doesn’t stop at deployment. We continuously monitor:
- Response quality and user feedback
- Shifts in user behavior
- Changes in business requirements or data formats
When performance begins to decline—perhaps due to new data types or shifting terminology—we fine-tune again with updated examples, ensuring the model stays aligned with its intended use case.
Techniques Used in Fine-Tuning
As we continue scaling and optimizing fine-tuned knowledge agents, it becomes increasingly important to apply efficient training techniques that ensure accuracy, reduce costs, and prevent common pitfalls like overfitting. From our hands-on experience training AI agents for enterprise clients, we’ve found that choosing the right combination of fine-tuning methods can mean the difference between a model that merely functions and one that excels. Below are the most widely used and effective techniques we incorporate into our fine-tuning workflows.
Full vs. Selective Fine-Tuning
The first strategic choice we make is whether to use full fine-tuning or selective fine-tuning.
- Full fine-tuning updates all layers and parameters in the foundation model. This approach is powerful when we have large, high-quality datasets and the computational budget to support multiple training epochs on GPU-intensive infrastructure. It’s ideal for use cases like medical imaging classification or contract summarization, where total domain adaptation is needed.
- Selective fine-tuning updates only a subset of the model’s layers, usually the later or task-specific ones. This is especially effective when working with smaller datasets, limited compute, or when we want to preserve the model’s general language capabilities. We’ve used this method successfully to fine-tune lightweight agents for sentiment analysis and anomaly detection in real-time applications.
Layer Freezing
One of the most important control mechanisms we apply during training is layer freezing. By locking the earlier layers, which hold broad language and reasoning knowledge, we prevent them from being altered by narrow, domain-specific examples. This protects the general intelligence of the model while allowing the later layers to specialize.
In a recent legal AI project, we froze over 90% of the foundational model and fine-tuned only the top layers using annotated contract data. This gave us the best of both worlds—a model fluent in language and sharp in legal context.
Hyperparameter Tuning
We never treat training parameters as static. Instead, we experiment with different learning rates, batch sizes, and epoch counts to find the combination that enables the model to converge efficiently.
- Lower learning rates allow for more stable, precise updates to model weights.
- Smaller batch sizes help when we have limited GPU memory or highly variable input lengths.
- More epochs give the model time to better internalize task-specific patterns, but we monitor closely to avoid overfitting.
We’ve seen firsthand how careful hyperparameter tuning can drastically improve F1 scores and output consistency, especially in domains like biomedical text generation and customer feedback classification.
Data Augmentation
When data is limited, we rely on data augmentation techniques to synthetically expand the dataset without changing its meaning. In text-based fine-tuning, this might involve:
- Rephrasing instruction-response pairs
- Swapping synonyms
- Generating paraphrased examples using other language models
In computer vision, common augmentations include rotation, cropping, and noise injection. This technique improves generalization and helps the model learn patterns more robustly, especially in tasks where overfitting is a real risk due to narrow data scopes.
Early Stopping
Another technique we often use is early stopping, where training is halted once the validation loss stops improving. This ensures we don’t waste compute cycles and also prevents the model from “memorizing” the data—one of the telltale signs of overfitting.
During one fine-tuning cycle for an e-commerce client, our validation loss plateaued at epoch 4, and we stopped training early. The final model was not only more efficient but also outperformed models trained for 10+ epochs in terms of precision and recall.
Regularization
To further prevent overfitting and ensure generalizable performance, we implement regularization techniques like:
- Dropout layers (during training)
- Weight decay to penalize extreme weight values
- Label smoothing to avoid overconfidence in classification tasks
These techniques are particularly effective when working with imbalanced datasets or when the model is exposed to noisy, unstructured inputs.
Ensemble Methods
In complex enterprise environments, we sometimes deploy ensemble models, where multiple fine-tuned agents are combined to improve prediction stability and reduce output variance. For example, in one case, we blended:
- A retrieval-augmented model (RAG)
- A classification-tuned model
- A summarization-focused model
Each handled a portion of the task, and the final output reflected the combined intelligence of all three—delivering a system that performed better than any single model on its own.
Learning Rate Scheduling
One advanced technique we use during long training runs is learning rate scheduling. Here, we dynamically lower the learning rate as training progresses, allowing the model to make more refined adjustments as it converges toward optimal performance. This is especially helpful in fine-tuning multi-step reasoning agents, where subtle context shifts matter a lot.
Transfer Learning vs. Fine-Tuning: A Clarification
It’s worth noting that fine-tuning is a specific type of transfer learning. In traditional transfer learning, we repurpose a pre-trained model by attaching new layers and training on a related task. However, fine-tuning goes deeper—by continuing to train the core model itself on domain-specific data, it embeds the knowledge directly into its internal weights.
This makes fine-tuned agents far more adaptable than those using static transfer learning setups. They don’t just borrow knowledge—they absorb it.
Benefits of Fine-Tuned Knowledge Agents
When we deploy fine-tuned knowledge agents, we’re not just enhancing a general-purpose LLM—we’re transforming it into a domain-aware assistant that delivers precise, relevant, and high-impact results. Over multiple deployments across industries like healthcare, legal tech, and SaaS support, we’ve experienced the real-world advantages of fine-tuning. These agents outperform generic models in accuracy, speed, and adaptability, while requiring fewer resources than training a model from scratch.
Let’s break down the benefits that make them essential for modern AI-driven systems.
Improved Accuracy on Specialized Tasks
One of the most immediate gains we see from fine-tuning is a significant boost in accuracy—especially on domain-specific inputs. General LLMs are great at understanding broad language patterns, but they can falter in highly specialized scenarios. When we fine-tune a model using carefully curated, labeled data, it learns the nuanced patterns and terminology of the target domain.
In one healthcare deployment, we fine-tuned a pre-trained model with anonymized patient notes and medical case studies. The resulting agent could interpret complex symptoms and deliver remarkably precise summaries, outperforming a generic GPT-based assistant by over 20% in accuracy.
Increased Relevance Through Contextual Adaptation
Generic AI agents can generate grammatically sound outputs, but they often lack the contextual relevance needed to truly serve business needs. Fine-tuned knowledge agents adapt to the specific taxonomy, tone, and workflows of a given domain. Because their internal parameters are optimized using real examples from your environment, they respond more appropriately in real-world interactions.
For instance, when we trained a customer support agent using instruction-response pairs from actual tickets, it learned not just how to answer, but how to do so in a friendly tone, with relevant policy references, and even apologies for common shipping delays—things a base model would miss entirely.
Efficiency in Terms of Compute and Data
Contrary to what many assume, fine-tuning doesn’t require massive resources. Because we begin with a pre-trained foundation model, we only need a smaller, focused dataset to fine-tune it for our specific use case. This drastically cuts down on the compute time, energy consumption, and storage requirements compared to training a model from scratch.
We’ve seen projects go live using just a few thousand well-annotated examples, running on cloud-based GPU infrastructure for a matter of hours—not weeks. This efficiency makes fine-tuning accessible even for smaller teams or startups operating on a budget.
Cost-Effectiveness vs. Training from Scratch
Training a large model from scratch involves millions of dollars, terabytes of data, and weeks of compute on high-performance GPUs. Fine-tuning, by contrast, allows us to leverage existing pre-trained models and invest our resources only in the final adaptation phase.
By focusing our efforts on task-specific customization, we can launch functional, intelligent agents that align with business goals at a fraction of the cost. This has allowed our clients—ranging from early-stage startups to enterprise organizations—to access the power of LLMs without making the leap into full-scale model development.
Specialized Knowledge and Expert-Level Outputs
Perhaps the most transformative benefit is the depth of specialized knowledge these agents gain. When we fine-tune with annotated contracts, biomedical literature, or industry-specific workflows, the agent begins to mirror expert-level performance.
In a real-world project involving legal tech, our fine-tuned model could not only identify key clauses in contracts but also summarize them in structured formats, complete with contextual explanations. These are outputs you’d expect from a trained legal analyst—not a machine.
Adaptability to Domain Shifts and User Feedback
Business environments change. Whether it’s new product lines, updated compliance regulations, or shifting user expectations, AI agents need to evolve too. Fine-tuned models offer us the flexibility to re-train quickly with new examples, often using just a subset of updated data.
What’s more, we actively integrate user feedback loops—where incorrect responses are flagged and incorporated back into the fine-tuning dataset. This keeps the agent not just functional, but continuously improving and aligned with our ever-evolving workflows.
We specialize in adapting large language models (LLMs) like GPT and LLaMA to your unique business needs. Explore our development services here.
Challenges and Considerations
As powerful as fine-tuned knowledge agents are, implementing them isn’t without its challenges. Over the years, we’ve helped teams across industries fine-tune LLMs for everything from customer service automation to clinical data analysis, and every successful project has required us to navigate trade-offs between efficiency, accuracy, and scalability. Knowing these limitations ahead of time allows us to design better systems and allocate resources effectively.
The Need for High-Quality Labeled Data
One of the most critical factors in the success of fine-tuning is access to high-quality, labeled datasets. Without properly annotated examples that reflect real-world scenarios, the model will struggle to learn the patterns, taxonomy, and tone needed to operate effectively.
Creating these datasets isn’t easy. It often requires manual annotation, domain expertise, and a strong understanding of input-output structure. For example, preparing a dataset in JSONL format with precise instruction-response pairs takes time and care. We’ve spent days—even weeks—curating examples that accurately represent the tasks the agent will face in production. But the payoff is worth it: with the right data, model performance improves dramatically.
Overfitting Risks
Another major consideration is the risk of overfitting. This happens when a model becomes too specialized in its training data, memorizing the content instead of learning generalizable patterns. As a result, it may perform well during training but struggle with unseen data or slightly altered inputs.
To address this, we use techniques like early stopping, dropout, and regularization. We also freeze earlier layers of the model to preserve general language understanding while fine-tuning only the task-specific components. Striking the right balance is an art: too little training and the model underperforms; too much, and it loses flexibility.
Compute Cost (Especially for Large LLMs)
While fine-tuning is far more cost-effective than training a model from scratch, it still demands substantial compute power—especially when working with large-scale LLMs like LLaMA or GPT derivatives.
We typically rely on cloud infrastructure with access to GPUs or TPUs, using services from providers like Oracle Cloud Infrastructure (OCI) or Hugging Face. However, compute-heavy tasks like multiple training epochs, hyperparameter tuning, and real-time monitoring can add up quickly, especially when training agents for complex, multi-step reasoning or multimodal data interpretation.
Time for Data Preparation and Training
Beyond compute, one of the most time-consuming phases is simply getting the data ready. From collection and cleaning, to annotation and formatting, the prep work can delay deployments if not planned for.
In one of our projects involving financial documents, the training itself took only 6 hours. But data preparation consumed more than a week, involving multiple rounds of cleaning, deduplication, and manual labeling. It’s a reminder that while fine-tuning is efficient, it’s not entirely turnkey—it requires hands-on work and patience.
Trade-Offs Between Generality and Specialization
Finally, perhaps the most philosophical challenge we face in fine-tuning is the trade-off between generality and specialization. The more we fine-tune a model to handle specific tasks, the better it performs in that narrow scope—but it can also lose flexibility and perform worse on broader tasks it was once good at.
This is why we often use selective fine-tuning, layer freezing, and learning rate scheduling to preserve the foundational strengths of the pre-trained model while still injecting domain-specific knowledge. It’s a balancing act, and one that varies by use case, data quality, and desired outcomes.
Fine-Tuning vs. Other Approaches
While fine-tuning offers unmatched domain specialization and task-specific performance, it’s not the only method we can use to optimize the outputs of large language models (LLMs). In many of our real-world deployments, we’ve combined or compared fine-tuning with prompt engineering and retrieval-augmented generation (RAG), depending on project goals, time constraints, and available infrastructure.
The table below outlines how these techniques differ across key dimensions:
| Method | What It Does | Pros | Cons |
|---|---|---|---|
| Fine-Tuning | Updates the internal weights of a pre-trained model using task-specific data to adapt it to a specialized domain. | – High accuracy on domain-specific tasks – Custom tone and structured outputs – Builds expert-level understanding |
– Requires labeled data – Risk of overfitting – Needs GPU infrastructure |
| Prompt Engineering | Crafts and optimizes input prompts to guide a model’s behavior without modifying the model itself. | – Quick to implement – Low cost – Easy to iterate and adjust |
– Limited control over output structure – Inconsistent responses – Less effective in narrow domains |
| RAG (Retrieval-Augmented Generation) | Integrates a search system with an LLM to fetch external documents and use them during response generation. | – Provides up-to-date information – Reduces hallucination – Expands knowledge beyond training data |
– Complex setup – Depends on retrieval quality – Higher compute and memory use |
The Future of Fine-Tuned Knowledge Agents
As we look ahead, it’s clear that fine-tuned knowledge agents are no longer just experimental tools—they’re becoming essential pillars in enterprise workflows, intelligent automation, and real-time decision-making. We’ve seen the rise of AI agents capable of writing code, generating reports, booking appointments, and even conducting legal or clinical analysis—all because they’ve been trained with domain-specific inputs using fine-tuning techniques.
With the increasing complexity of tasks and the growing need for adaptive intelligence, we expect fine-tuned agents to not only become more capable, but also more autonomous and collaborative. They won’t just answer queries—they’ll manage end-to-end processes, handle exceptions, trigger system-level actions, and evolve in tandem with business needs.
Automation of Fine-Tuning: AutoML, RLHF & Dynamic Retraining
One of the most exciting shifts on the horizon is the automation of the fine-tuning process itself. Techniques like AutoML (automated machine learning) and reinforcement learning with human feedback (RLHF) are making it easier for teams—especially those without deep ML expertise—to fine-tune and retrain models as use cases evolve.
We’ve begun integrating dynamic retraining loops in several projects, where user feedback, error logs, or shifting document structures trigger on-the-fly updates to the model’s performance. This ensures that agents remain aligned with real-world usage without needing to be rebuilt from scratch.
Expansion to Multimodal Tasks: Text, Vision, Audio & More
While fine-tuning has primarily focused on text-based LLMs, we’re now seeing rapid expansion into multimodal domains. This includes computer vision (image recognition, video summarization), audio processing (transcription, emotion detection), and multilingual workflows where models handle text, speech, and visuals together.
In recent prototypes, we’ve fine-tuned agents to analyze medical X-rays, extract insights from satellite imagery, and cross-reference them with textual patient data—delivering more comprehensive outputs than any single-modality system could.
The future of fine-tuning is not just larger models—it’s more connected models, trained to understand, interpret, and act across multiple modalities.
Context-Aware Fine-Tuning Pipelines
One promising trend we’re actively experimenting with is context-aware fine-tuning. Instead of treating every input as static, these pipelines adapt to changing context—be it a new customer, updated policies, or real-time environmental data.
Imagine a travel planning agent that re-trains on live airfare and hotel feeds, or a compliance bot that fine-tunes itself weekly based on regulatory updates. With layer freezing, learning rate scheduling, and small-batch updates, these agents can evolve continually—without sacrificing their core understanding.
This leads to hyper-adaptive knowledge agents that get smarter with use, without needing a full development cycle.
Role in Enterprise and Cloud-Native AI Platforms
At the enterprise level, cloud-native ecosystems are making it easier to deploy, manage, and monitor fine-tuned knowledge agents at scale. Platforms like Oracle Cloud Infrastructure (OCI), Google Vertex AI, and Hugging Face AutoTrain now offer end-to-end solutions for everything from data ingestion and preprocessing to training orchestration and model versioning.
We’ve worked with clients who’ve gone from raw customer feedback to a fully operational fine-tuned agent in less than two weeks—thanks to robust MLOps pipelines, JupyterLab environments, and seamless GPU provisioning in the cloud.
In the future, deploying a fine-tuned agent will feel less like a complex dev task and more like plug-and-play software onboarding, where businesses adapt AI to their needs in real time.
Conclusion
Fine-tuned knowledge agents combine the general intelligence of LLMs with the specialization needed for real-world tasks. By training these agents on high-quality, domain-specific data, we unlock better accuracy, adaptability, and contextual understanding—without the cost of full-scale model development.
For businesses and AI teams, the future lies in this balance: general-purpose language power paired with expert-level precision. That’s where fine-tuning delivers its most transformative results.